Ya hemos hablado en muchas ocasiones sobre la cantidad ingente de datos que existen en el sector de recambios de vehículos y el hecho de que continuamente van apareciendo nuevos datos.
Pero, cuando nos centramos en segmentos de aplicación específicos como el Industrial, Agrícola o Marino, entre otros, la complejidad se acentúa y tanto los mecanismos de organización de datos que disponemos como las herramientas tradicionales para el análisis de productos que utilizamos, no nos sirven.
Como es obvio, para poder analizar cualquier segmento de aplicación necesitamos disponer de los datos sobre todos los productos existentes.
Las empresas, ya sean fabricantes o distribuidores, crean su propia codificación de referencias para así definir el universo de productos que quiere trabajar y/o analizar. Estas codificaciones propias, organizan los miles de productos existentes y las millones de referencias OE, OEM y IAM, a partir de 2 estructuras de datos distintas:
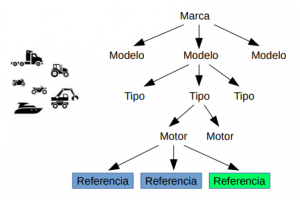
1) Aplicaciones. Se asocian los códigos propios con una estructura de vehículos estándar, donde también podemos encontrar asociadas a otras referencias OE, OEM y IAM.
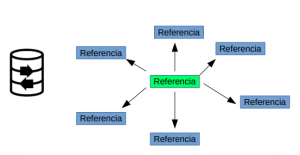
2) Equivalencias. Se vincula los códigos propios con las referencias OE, OEM y IAM que se quieran organizar.
La mayoría de empresas mantienen ambas estructuras de datos, aunque algunas sólo definen equivalencias. En cualquier caso, deben emplear una ingente cantidad de recursos humanos y de tiempo para mantener actualizadas estas estructuras de datos.
Estas estructuras de datos son de suma importancia pues son utilizadas continuamente en todos los procesos de búsqueda y análisis que se realizan dentro de cada empresa.
Pero, ¿Qué problemas estructurales presentan estas estructuras de datos cuando queremos analizar segmentos de aplicación muy determinados como el Industrial, Agrícola o Marino?
1) Aplicaciones
No existe un parque de vehículos universal que defina todas las aplicaciones. Esto imposibilita detectar vía aplicaciones todos los productos existentes.
No conocemos la aplicación de muchas referencias, con lo cual muchos productos no pueden ser asignados a ninguna aplicación.
Una referencia puede estar asociada a varias aplicaciones y una aplicación a varias referencias, lo cual genera muchas imprecisiones.
2) Equivalencias
Ninguna codificación existente relaciona más del 60% del total de referencias OE/OEM/IAM que existen en el mercado. Por lo tanto, el análisis a partir de una única codificación es siempre limitado.
Cada codificación utiliza criterios de agrupación de referencias distintos, lo cual dificulta enormemente el poder combinarlas para así intentar ampliar el análisis.
Por estos motivos, podemos decir de manera rotunda que todas las empresas tienen una visión de los datos que es:
INCOMPLETA, IMPRECISA y COMPLEJA
Y ahora que conocemos las limitaciones de estas estructuras de datos para analizar el mercado, nos podemos preguntar: ¿existe algún mecanismo que nos ayude a analizar todos los productos existentes en el mercado de una forma COMPLETA, PRECISA y SENCILLA?
La respuesta es, si. Factory Data ha desarrollado una tecnología disruptiva que es capaz de solucionar estos problemas estructurales de los datos.
La solución consiste en utilizar un método totalmente independiente de las estructuras de datos de aplicaciones, que ya hemos visto que son imprecisas pero sobre todo incompletas, y en su lugar utilizar de forma conjunta las estructuras de datos de equivalencias de los principales proveedores del mercado, para combinarlas a partir de un algoritmo propio de clusterización y así disponer de una visión lo más completa posible de todo el conocimiento existente.
Gracias a esta estructura de datos totalmente novedosa, nos permite ofrecer servicios disruptivos como el análisis de la demanda, que es calculada con máxima precisión, en productos de cualquier segmento de aplicación, pero en especial, para el Industrial, Agrícola y Marino.
En el próximo artículo explicaremos más en detalle en que consiste esta estructura de datos y como nos permite disponer de una visión del mercado: COMPLETA, PRECISA y SENCILLA.